blog
9 Tips for Going in Production with Galera Cluster for MySQL

Are you going in production with Galera Cluster for MySQL? Here are 9 tips to consider before going live. These are applicable to all 3 Galera versions (Codership, Percona XtraDB Cluster and MariaDB Galera Cluster).
1. Galera strengths and weaknesses
There are multiple types of replication and cluster technologies for MySQL, make sure you understand how Galera works so you set the right expectations. Applications that run on single instance MySQL might not work well on Galera, you might need to make some changes to the application or the workload might not be appropriate. We’d suggest you have a look at these resources:
- Tutorial on Galera Cluster
- Is Synchronous Replication Right for your App
- MariaDB Galera Cluster – Known Limitations
- Webinar: Migrating to Galera Cluster
2. Database schema
Synchronous replication has implications on how well some transactions will run, so consider the following:
- Each table must have at least one explicit primary key defined.
- Each table must run under InnoDB or XtraDB storage engine.
- Chunk up your big transaction in batches. For example, rather than having one transaction insert 100,000 rows, break it up into smaller chunks of e.g., insert 1000 rows per transaction.
- Your application can tolerate non-sequential auto-increment values.
- Schema changes are handled differently. Watch this webinar for details.
- Handle hotspots/Galera deadlocks by sending writes to a single node.
3. Hardware and network
Galera will perform as fast as the slowest node. This is due to the nature of synchronous replication, where all nodes need to acknowledge a writeset before committing. Choosing uniform hardware for all nodes is recommended. If you’re running on virtualized environments, monitor CPU Steal Time (the percentage of time a virtual CPU waits for a real CPU while the hypervisor is servicing another virtual processor).
The disk subsystem is important (and also applies to single instance MySQL). Remember that upgrading the disk layer is a bigger hassle than upgrading the other components like RAM or network interface card. Hardware upgrades can be performed in round-robin fashion, i.e upgrading one node at a time.
If you are deploying on multiple datacenters across WAN, please ensure that the WAN links are reliable with predictable latency. Latency variance is also important, as large fluctuations might trigger timeouts within Galera. If you have concerns around data privacy and security, you might want to encrypt the WAN replication traffic. If firewalls are enabled on the nodes, make sure you open these ports. For AWS, please refer to this post on security groups.
4. Recovery from failure
If you’re moving to a clustered database, high availability is probably important so make sure you’re prepared for unplanned downtime events. Kill nodes at random and see if they recover. Simulate scenarios like power failures, nodes running out of disk space, Galera nodes running out of MySQL connections, unplugged network cables and other similar type situations. If you bring down a node or cluster and it does not recover automatically, examine the respective log files, study the behaviour during the downtime and try to recover manually if possible. Document your findings for future reference.
Look also into planned events that could potentially be disruptive to your operations, including software and hardware upgrades, configuration changes, schema changes or restoring data from backup. Rehearse these at least once before you go live.
For more details, check out this webinar on how to repair and recover your database clusters. This blog shows you how to do a full restore of a MariaDB Galera Cluster. And if you really want a belts and suspenders approach, why not have Galera replicate asynchronously to a MySQL slave?
5. Tune your Galera nodes
Tune the Galera nodes based on your workload and resources. Standard MySQL and InnoDB optimization can be applied here for buffers, caches, threads, queries, and indexing. Certain parameters can be relaxed in Galera e.g. innodb_flush_log_at_trx_commit and sync_binlog can be set to 0.
Perform benchmarks to determine if the changes are beneficial. Even if you are deploying manually, you might want to create a Galera configuration using the Severalnines Configurator and see how the parameters have been tuned.
6. Monitoring
Monitoring the health of the databases, identifying performance problems, understanding symptoms that indicate insufficient or unstable resources are all important tasks for a DB or system administrator. Make sure you monitor everything from host/network/disk/memory stats to processes, MySQL variables, queries, uptime, flow control, backups and log files.
Monitoring data can also be useful when doing future capacity planning. Get to know your peak hours so you can schedule a less costly maintenance window, and predict when you can start to scale your database cluster.
You might want to check out ClusterControl, most of the monitoring features are available for free in the Community Edition.
7. Backup your data
Pick the Galera node with the least load to do your backups. For instance, some users dedicate a node for adhoc reporting and backups. On the selected node, enable binary logging if you want to do point-in-time recovery. Backup all possible data including your database’s schema structure and data using logical (mysqldump) and binary backups (xtrabackup), binary logs and storage snapshots. Test your backups by restoring them to a test cluster, and measure the recovery times. Do this at least once per calendar quarter.
Allocate enough space in the database server for 1-2 days of local backups. Store daily backups in the local datacenter for 4 weeks as well as monthly backup for 1 year. Once a year, create an off-site encrypted and archived annual backup to a remote datacenter or cloud provider. Continuous transfer of backup files to remote datacenters can be easily done using BitTorrent Sync.
You will find useful backup recommendations in this Percona whitepaper (registration required).
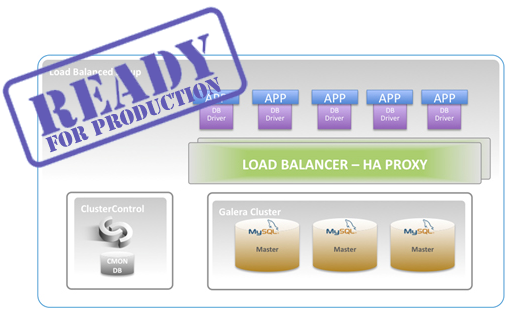
8. Use a Load Balancer
Use a load balancer to control access to your Galera nodes. It is a great way of spreading the application load between the database instances, as well as restricting access, e.g., if you want to take a node offline for maintenance, or if you want to limit the number of connections opened on the Galera nodes – the load balancer should be able to queue connections and therefore provide some overload protection.
Virtual IP and KeepAlived provides a single endpoint with the ability to failover to more than one physical network interface. Combining these provides a simple and reliable way for your applications to access the database cluster.
For more information, check out this tutorial on how to use HAProxy for SQL load balancing.
9. Manage and Automate
Cluster configurations tend to be complex, but once they are designed, it is possible to duplicate them with minimal variation. Automation can be applied to provisioning, upgrading, patching and scaling. For instance, changing a non-dynamic variable in a configuration file requires you to repeat the same tasks n times (n = number of Galera nodes), as well as rolling restarts and verifications to check the new configuration has correctly loaded. As an infrastructure grows, you might need to provision new clusters for upgrade testing, benchmarking, troubleshooting, etc. DBAs can focus on more critical tasks like performance tuning, query design, data modelling or providing architectural advice to application developers.
Check out this webinar to see how you can manage your Galera cluster using ClusterControl.
There is a lot of information in this post, and there’s probably more things to consider before putting Galera in production. Do let us know what we’ve missed. Happy clustering!



