blog
How to Set Up Asynchronous Replication from Galera Cluster to Standalone MySQL server with GTID

Hybrid replication, i.e. combining Galera and asynchronous MySQL replication in the same setup, became much easier since GTID got introduced in MySQL 5.6. Although it was fairly straightforward to replicate from a standalone MySQL server to a Galera Cluster, doing it the other way round (Galera → standalone MySQL) was a bit more challenging. At least until the arrival of GTID.
There are a few good reasons to attach an asynchronous slave to a Galera Cluster. For one, long-running reporting/OLAP type queries on a Galera node might slow down an entire cluster, if the reporting load is so intensive that the node has to spend considerable effort coping with it. So reporting queries can be sent to a standalone server, effectively isolating Galera from the reporting load. In a belts and suspenders approach, an asynchronous slave can also serve as a remote live backup.
In this blog post, we will show you how to replicate a Galera Cluster to a MySQL server with GTID, and how to failover the replication in case the master node fails.
Hybrid Replication in MySQL 5.5
In MySQL 5.5, resuming a broken replication requires you to determine the last binary log file and position, which are distinct on all Galera nodes if binary logging is enabled. We can illustrate this situation with the following figure:
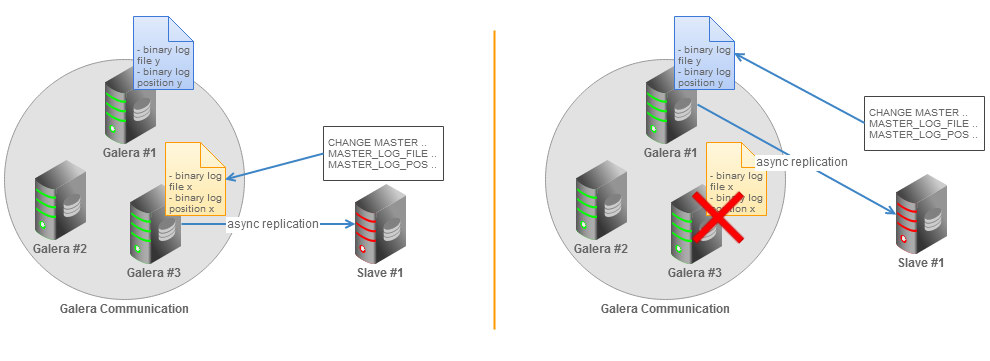
If the MySQL master fails, replication breaks and the slave will need to switch over to another master. You will need pick a new Galera node, and manually determine a new binary log file and position of the last transaction executed by the slave. Another option is to dump the data from the new master node, restore it on slave and start replication with the new master node. These options are of course doable, but not very practical in production.
How GTID Solves the Problem
GTID (Global Transaction Identifier) provides a better transactions mapping across nodes, and is supported in MySQL 5.6. In Galera Cluster, all nodes will generate different binlog files. The binlog events are the same and in the same order, but the binlog file names and offsets may vary. With GTID, slaves can see a unique transaction coming in from several masters and this could easily being mapped into the slave execution list if it needs to restart or resume replication.
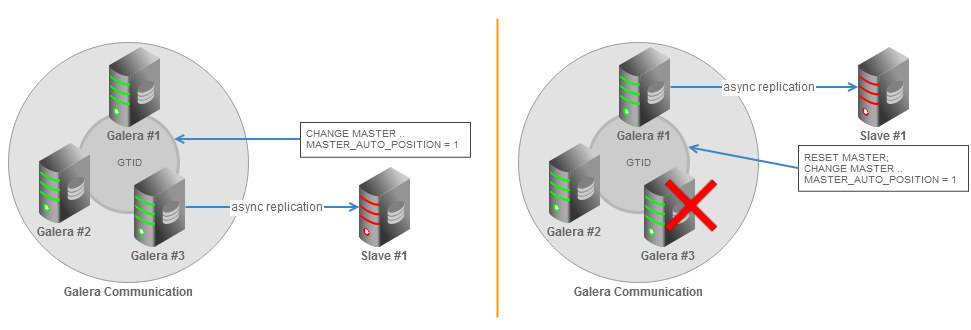
All necessary information for synchronizing with the master is obtained directly from the replication stream. This means that when you are using GTIDs for replication, you do not need to include MASTER_LOG_FILE or MASTER_LOG_POS options in the CHANGE MASTER TO statement. Instead it is necessary only to enable the MASTER_AUTO_POSITION option. You can find more details about the GTID in the MySQL Documentation page.
Setting Up Hybrid Replication by Hand
Make sure the Galera nodes (masters) and slave(s) are running on MySQL 5.6 before proceeding with this setup. We have a database called sbtest in Galera, which we will replicate to the slave node.
1. Enable required replication options by specifying the following lines inside each DB node’s my.cnf (including the slave node):
For master (Galera) nodes:
gtid_mode=ON
log_bin=binlog
log_slave_updates=1
enforce_gtid_consistency
expire_logs_days=7
server_id=1 # 1 for master1, 2 for master2, 3 for master3
binlog_format=ROWFor slave node:
gtid_mode=ON
log_bin=binlog
log_slave_updates=1
enforce_gtid_consistency
expire_logs_days=7
server_id=101 # 101 for slave
binlog_format=ROW
replicate_do_db=sbtest
slave_net_timeout=602. Perform a cluster rolling restart of the Galera Cluster (from ClusterControl UI > Manage > Upgrade > Rolling Restart). This will reload each node with the new configurations, and enable GTID. Restart the slave as well.
3. Create a slave replication user and run following statement on one of the Galera nodes:
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY 'slavepassword';4. Log into the slave and dump database sbtest from one of the Galera nodes:
$ mysqldump -uroot -p -h192.168.0.201 --single-transaction --skip-add-locks --triggers --routines --events sbtest > sbtest.sql5. Restore the dump file onto the slave server:
$ mysql -uroot -p < sbtest.sql6. Start replication on the slave node:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.201', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;To verify that replication is running correctly, examine the output of slave status:
mysql> SHOW SLAVE STATUSG
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...Setting up Hybrid Replication Using ClusterControl
In the previous paragraph we described all the necessary steps to enable the binary logs, restart the cluster node by node, copy the data and then setup replication. The procedure is a tedious task and you can easily make errors in one of these steps. In ClusterControl we have automated all the necessary steps.
1. For ClusterControl users, you can go to the nodes in the Nodes page and enable binary logging.
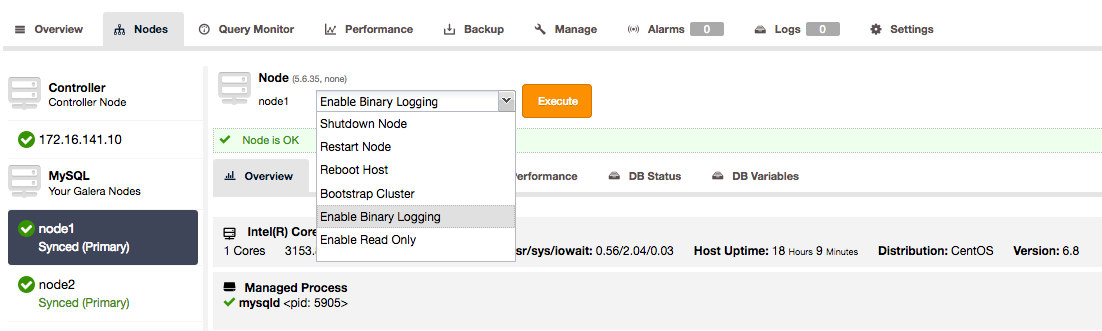
This will open a dialogue that allows you to set the binary log expiration, enable GTID and auto restart.
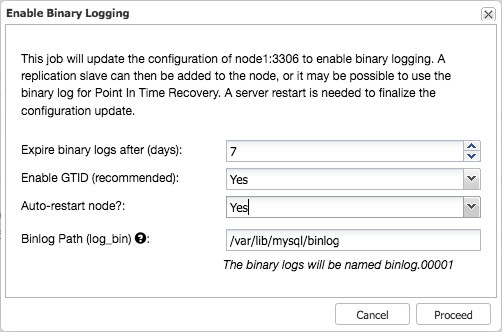
This initiates a job, that will safely write these changes to the configuration, create replication users with the proper grants and restart the node safely.
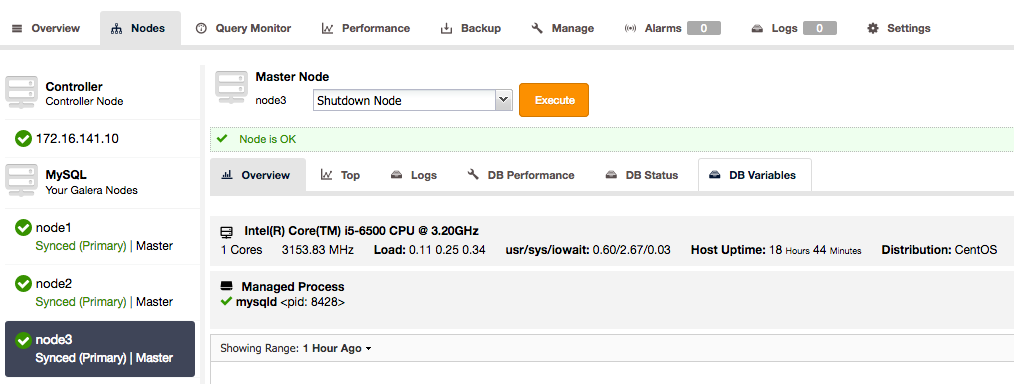
Repeat this process for each Galera node in the cluster, until all nodes indicate they are master.
2. Add the asynchronous replication slave to the cluster
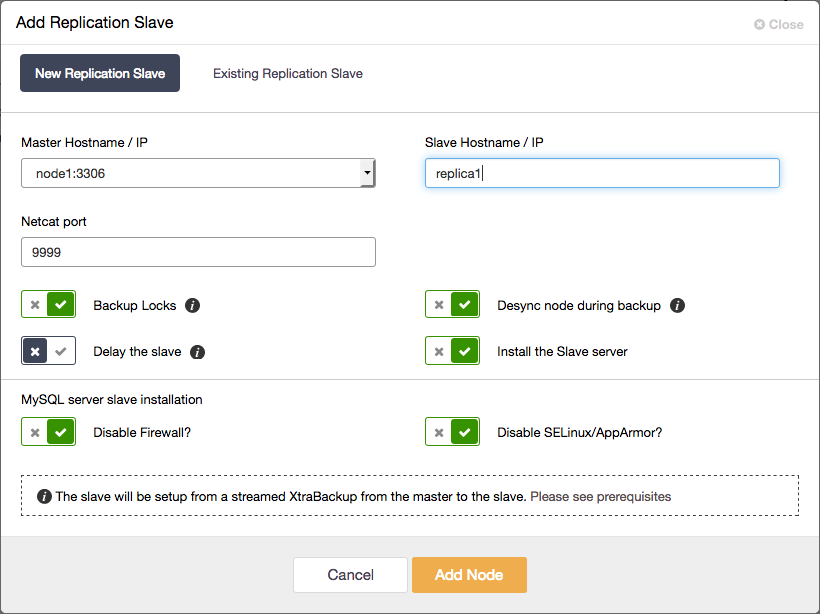
And this is all you have to do. The entire process described in the previous paragraph has been automated by ClusterControl.
Changing Master
If the designated master goes down, the slave will retry to reconnect again in slave_net_timeout value (our setup is 60 seconds - default is 1 hour). You should see following error on slave status:
Last_IO_Errno: 2003
Last_IO_Error: error reconnecting to master '[email protected]:3306' - retry-time: 60 retries: 1Since we are using Galera with GTID enabled, master failover is supported via ClusterControl when Cluster and Node Auto Recovery has been enabled. Whether the master would fail due to network connectivity or any other reason, ClusterControl will automatically fail over to the most suitable other master node in the cluster.
If you wish to perform the failover manually, simply change the master node as follows:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.202', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;In some cases, you might encounter a “Duplicate entry .. for key” error after the master node changed:
Last_Errno: 1062
Last_Error: Could not execute Write_rows event on table sbtest.sbtest; Duplicate entry '1089775' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log mysqld-bin.000009, end_log_pos 85789000In older versions of MySQL, you can just use SET GLOBAL SQL_SLAVE_SKIP_COUNTER = n to skip statements, but it does not work with GTID. Miguel from Percona wrote a great blog post on how to repair this by injecting empty transactions.
Another approach, for smaller databases, could also be to just get a fresh dump from any of the available Galera nodes, restore it and use RESET MASTER statement:
mysql> STOP SLAVE;
mysql> RESET MASTER;
mysql> DROP SCHEMA sbtest; CREATE SCHEMA sbtest; USE sbtest;
mysql> SOURCE /root/sbtest_from_galera2.sql; -- repeat step #4 above to get this dump
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.202', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;You may also use pt-table-checksum to verify the replication integrity, more information in this blog post.
Note: Since in MySQL replication the slave applier is by default still single-threaded, do not expect the async replication performance to be the same as Galera’s parallel replication. For MySQL 5.6 and 5.7 there are options to make the asynchronous replication executed in parallel on the slave nodes, but in principle this replication is still depending on the correct order of transactions inside the same schema to happen. If the replication load is intensive and continuous, the slave lag will just keep growing. We have seen cases where slave could never catch up with the master.



