blog
How to Change AWS Instance Sizes for Your Galera Cluster and Optimize Performance

Running your database cluster on AWS is a great way to adapt to changing workloads by adding/removing instances, or by scaling up/down each instance. At Severalnines, we talk much more about scale-out than scale up, but there are cases where you might want to scale up an instance instead of scaling out.
![]()
In this post, we’ll show you how to change instance sizes with respect to RAM, CPU and IOPS, and how to tune your Galera nodes accordingly. Moreover, this post assumes that instances are launched using Amazon VPC.
When do we need to upgrade an instance?
You typically need to upgrade an instance when you run out of server resources. This includes CPU, RAM, storage capacity, disk throughput and bandwidth. You must allow enough headroom for your database to operate and grow. Performance tuning will allow you to get the most out of your servers, but in some cases, this might not be enough.
Here is a list of symptoms that usually indicate a lack of resources:
- Server starts swapping. Swapping causes parts of the content in memory to be written to disk. This is really bad for MySQL performance.
- Out of Memory (OOM) error appearing in dmesg. MySQL will typically use the most memory out of all processes running on your database servers.
- CPU usage (usr/sys/iowait/steal) is constantly at its peak.
- More applications starting to use your database instances, bringing more data and load.
ClusterControl has a number of performance advisors that can indicate a lack of resources allocated to your database nodes, e.g. low cache hit ratios or inappropriate memory configurations. Some of you might even have seen alarms like the below:
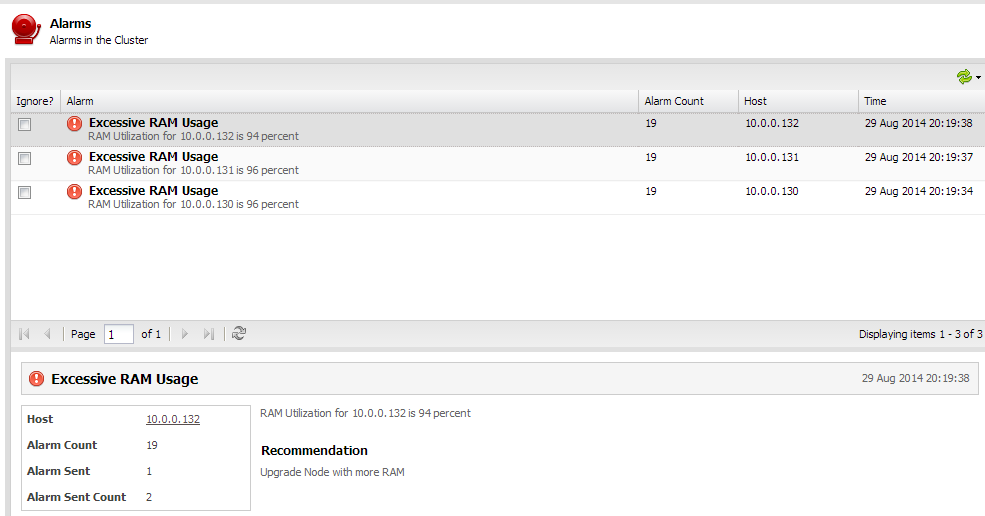
Upgrading Instances
Upgrades or downgrades of instances can be done in a rolling fashion, one node at a time, until the whole cluster is upgraded. This means your cluster will be online all the time. If possible, perform some simple benchmarks before and after the upgrade exercise to understand how performance has changed.
Now, let’s see how we can change the instance size for our Galera nodes. In this example, we have a three-node Galera Cluster running on m3.medium EC2 instances (1 vCPU, 3.75 GB memory). We will upgrade to bigger instances, m3.xlarge (4 vCPU, 15GB memory). All instances are running on Amazon VPC, with dedicated internal IP assigned.
1. Stop the first database node from the ClusterControl UI:
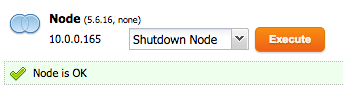
Since the shutdown is user-initiated, ClusterControl will not try to recover the node.
2. Stop the corresponding node via AWS Management Console or command line:
$ init 0
3. From the AWS console, select the corresponding node > Actions > Change Instance Type > and change to a bigger instance type:
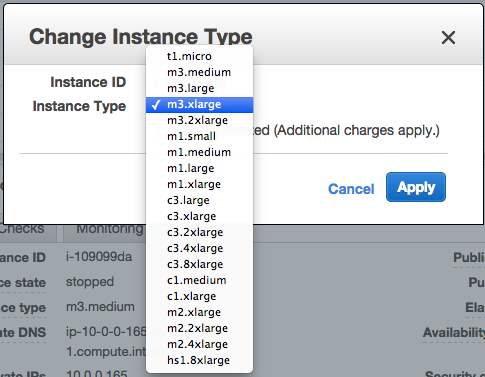
4. Start the node via the AWS Management Console.
5. Once the node is online, tune at least the innodb_buffer_pool_size. More on this further down under ‘Performance Tuning’.
6. Start the node from the ClusterControl UI:
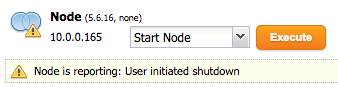
Wait for the node to sync with the cluster. Once finished, instance upgrade for the first node is completed. Repeat these steps for the remaining nodes until all the nodes have been upgraded. If this is a production system, perform this exercise during non-peak hours.
Performance Tuning
If you deployed your Galera Cluster using the Severalnines Configurator, the configuration would have been tweaked according to the hardware specification and platform. Just adding more resources may not result in improvements if the server variables are not set to make use of these available resources.
After the upgrade, certain MySQL parameters need to be adjusted accordingly. You can use Percona Tools, MySQL Memory Calculator or even the Severalnines Configurator to generate a new configuration file and see what parameters to change.
Memory
The memory configuration has to be set correctly to reflect the specific circumstances. As our test case, we would recommend user to adjust following parameters:
- innodb_buffer_pool_size = [The is the most important part. Set to 60%-80% of total memory. Do not set it to more than 80% of physical memory.]
- innodb_buffer_pool_instances = [1 instance/1 GB buffer pool. So if you have 8GB, 8 instances is recommended. Max value is 64.]
Disk
If you increase the disk’s IOPS, you can adjust the following:
- innodb_io_capacity = [Equal to the number of new IOPS, consider dedicating 50-100% to MySQL.]
If you increase the the disk space, you can adjust the following:
- wsrep_provider_options = ”gcache.size=[Less or equal to half of the size of your database, decreases recovery time.]”
CPU Cores
If you increase CPU cores, the following can help:
- wsrep_slave_thread = [4 x CPU cores]
Post-Upgrade Checkups
Once the full upgrade has completed, check out the performance advisors by going to the Health Report tab in ClusterControl. You will get a summary of how your Galera nodes are faring in different areas (memory, innodb, cache, locking, etc.). Ensure all indicators are green:
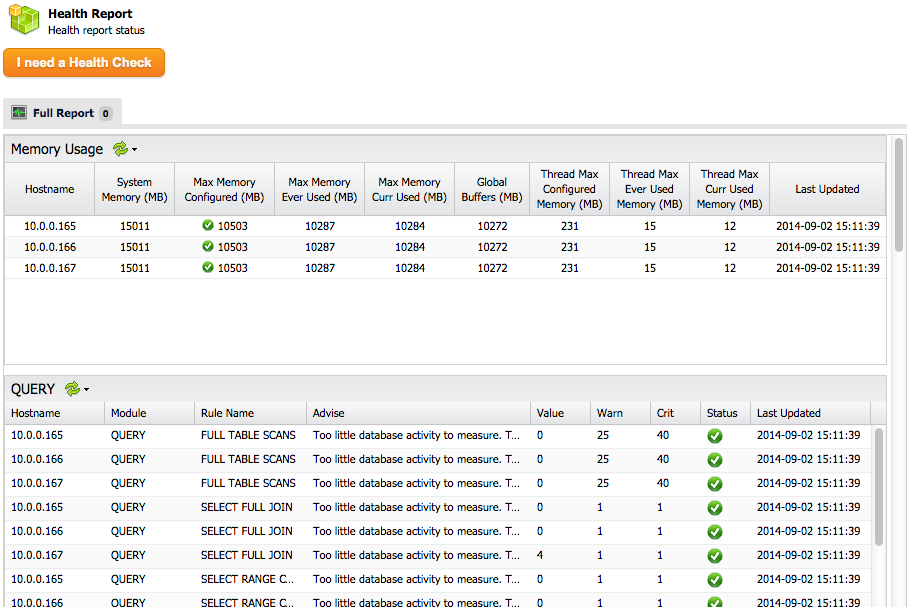
That’s it folks, happy vertical elasticity!