blog
Online Schema Upgrade in MySQL Galera Cluster Using RSU Method


This post is a continuation of our previous post on Online Schema Upgrade in Galera using TOI method. We will now show you how to perform a schema upgrade using the Rolling Schema Upgrade (RSU) method.
RSU and TOI
As we discussed, when using TOI, a change happens at the same time on all of the nodes. This can become a serious limitation as such way of executing schema changes implies that no other queries can be executed. For long ALTER statements, the cluster may be not available for hours even. Obviously, this is not something you can accept in production. RSU method addresses this weakness – changes happen on one node at a time while other nodes are not affected and can serve traffic. Once ALTER completes on one node, it will rejoin the cluster and you can proceed with executing a schema change on the next node.
Such behavior comes with its own set of limitations. The main one is that scheduled schema change has to be compatible. What does it mean? Let’s think about it for a while. First of all we need to keep in mind that the cluster is up and running all the time – the altered node has to be able to accept all of the traffic which hit the remaining nodes. In short, a DML executed on the old schema has to work also on the new schema (and vice-versa if you use some sort of round-robin-like connection distribution in your Galera Cluster). We will focus on the MySQL compatibility, but you also have to remember that your application has to work with both altered and non-altered nodes – make sure that your alter won’t break the application logic. One good practice is to explicitly pass column names to queries – don’t rely on “SELECT *” because you never know how many columns you’ll get in return.
Galera and Row-based binary log format
Ok, so DML has to work on old and new schemas. How are DML’s transferred between Galera nodes? Does it affect what changes are compatible and what are not? Yes, indeed – it does. Galera does not use regular MySQL replication but it still relies on it to transfer events between the nodes. To be precise, Galera uses ROW format for events. An event in row format (after decoding) may look like this:
### INSERT INTO `schema`.`table`
### SET
### @1=1
### @2=1
### @3='88764053989'
### @4='14700597838'Or:
### UPDATE `schema`.`table`
### WHERE
### @1=1
### @2=1
### @3='88764053989'
### @4='14700597838'
### SET
### @1=2
### @2=2
### @3='88764053989'
### @4='81084251066'As you can see, there is a visible pattern: a row is identified by its content. There are no column names, just their order. This alone should turn on some warning lights: “what would happen if I remove one of the columns?” Well, if it is the last column, this is acceptable. If you would remove a column in the middle, this will mess up with the column order and, as a result, replication will break. Similar thing will happen if you add some column in the middle, instead of at the end. There are more constraints, though. Changing column definition will work as long as it is the same data type – you can alter INT column to become BIGINT but you cannot change INT column into VARCHAR – this will break replication. You can find detailed description of what change is compatible and what isn’t in the MySQL documentation. No matter what you can see in the documentation, to stay on the safe side, it’s better to run some tests on a separate development/staging cluster. Make sure it will work not only according to the documentation, but that it also works fine in your particular setup.
All in all, as you can clearly see, performing RSU in a safe way is much more complex than just running couple of commands. Still, as commands are important, let’s take a look at the example of how you can perform the RSU and what can go wrong in the process.
RSU Example
Initial setup
Let’s imagine a rather simple example of an application. We will use a bechmark tool, Sysbench, to generate content and traffic, but the flow will be the same for almost every application – WordPress, Joomla, Drupal, you name it. We will use HAProxy collocated with our application to split reads and writes among Galera nodes in a round-robin fashion. You can check below how HAProxy sees the Galera cluster.

Whole topology looks like below:
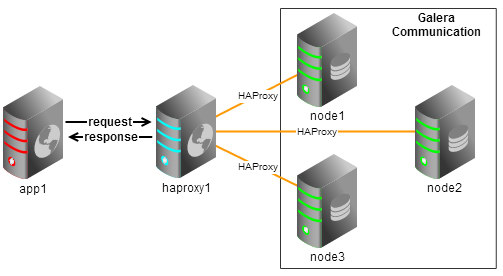
Traffic is generated using the following command:
while true ; do sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --max-requests=0 --time=3600 --mysql-host=10.0.0.100 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3307 --tables=32 --report-interval=1 --skip-trx=on --table-size=100000 --db-ps-mode=disable run ; doneSchema looks like below:
mysql> SHOW CREATE TABLE sbtest1.sbtest1G
*************************** 1. row ***************************
Table: sbtest1
Create Table: CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
) ENGINE=InnoDB AUTO_INCREMENT=29986632 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)First, let’s see how we can add an index to this table. Adding an index is a compatible change which can be easily done using RSU.
mysql> SET SESSION wsrep_OSU_method=RSU;
Query OK, 0 rows affected (0.00 sec)mysql> ALTER TABLE sbtest1.sbtest1 ADD INDEX idx_new (k, c);
Query OK, 0 rows affected (5 min 19.59 sec)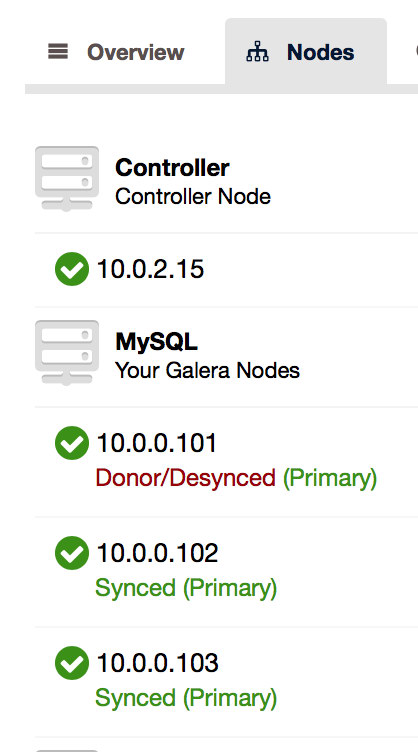
As you can see in the Node tab, the host on which we executed the change has automatically switched to Donor/Desynced state which ensures that this host will not impact the rest of the cluster if it gets slowed down by the ALTER.
Let’s check how our schema looks now:
mysql> SHOW CREATE TABLE sbtest1.sbtest1G
*************************** 1. row ***************************
Table: sbtest1
Create Table: CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`),
KEY `idx_new` (`k`,`c`)
) ENGINE=InnoDB AUTO_INCREMENT=29986632 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)As you can see, the index has been added. Please keep in mind, though, this happened only on that particular node. To accomplish a full schema change, you have to follow this process on the remaining nodes of the Galera Cluster. To finish with the first node, we can switch wsrep_OSU_method back to TOI:
SET SESSION wsrep_OSU_method=TOI;
Query OK, 0 rows affected (0.00 sec)We are not going to show the remainder of the process, because it’s the same – enable RSU on the session level, run ALTER, enable TOI. What’s more interesting is what would happen if the change will be incompatible. Let’s take again a quick look at the schema:
mysql> SHOW CREATE TABLE sbtest1.sbtest1G
*************************** 1. row ***************************
Table: sbtest1
Create Table: CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`),
KEY `idx_new` (`k`,`c`)
) ENGINE=InnoDB AUTO_INCREMENT=29986632 DEFAULT CHARSET=latin1
1 row in set (0.00 sec)Let’s say we want to change the type of column ‘k’ from INT to VARCHAR(30) on one node.
mysql> SET SESSION wsrep_OSU_method=RSU;
Query OK, 0 rows affected (0.00 sec)mysql> ALTER TABLE sbtest1.sbtest1 MODIFY COLUMN k VARCHAR(30) NOT NULL DEFAULT '';
Query OK, 10004785 rows affected (1 hour 14 min 51.89 sec)
Records: 10004785 Duplicates: 0 Warnings: 0Now, lets take a look at the schema:
mysql> SHOW CREATE TABLE sbtest1.sbtest1G
*************************** 1. row ***************************
Table: sbtest1
Create Table: CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` varchar(30) NOT NULL DEFAULT '',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`),
KEY `idx_new` (`k`,`c`)
) ENGINE=InnoDB AUTO_INCREMENT=29986632 DEFAULT CHARSET=latin1
1 row in set (0.02 sec)Everything is as we expect – ‘k’ column has been changed to VARCHAR. Now we can check if this change is acceptable or not for the Galera Cluster. To test it, we will use one of remaining, unaltered nodes to execute the following query:
mysql> INSERT INTO sbtest1.sbtest1 (k, c, pad) VALUES (123, 'test', 'test');
Query OK, 1 row affected (0.19 sec)
It definitely doesn’t look good – our node is down. Logs will give you more details:
2017-04-07T10:51:14.873524Z 5 [ERROR] Slave SQL: Column 1 of table 'sbtest1.sbtest1' cannot be converted from type 'int' to type 'varchar(30)', Error_code: 1677
2017-04-07T10:51:14.873560Z 5 [Warning] WSREP: RBR event 3 Write_rows apply warning: 3, 982675
2017-04-07T10:51:14.879120Z 5 [Warning] WSREP: Failed to apply app buffer: seqno: 982675, status: 1
at galera/src/trx_handle.cpp:apply():351
Retrying 2th time
2017-04-07T10:51:14.879272Z 5 [ERROR] Slave SQL: Column 1 of table 'sbtest1.sbtest1' cannot be converted from type 'int' to type 'varchar(30)', Error_code: 1677
2017-04-07T10:51:14.879287Z 5 [Warning] WSREP: RBR event 3 Write_rows apply warning: 3, 982675
2017-04-07T10:51:14.879399Z 5 [Warning] WSREP: Failed to apply app buffer: seqno: 982675, status: 1
at galera/src/trx_handle.cpp:apply():351
Retrying 3th time
2017-04-07T10:51:14.879618Z 5 [ERROR] Slave SQL: Column 1 of table 'sbtest1.sbtest1' cannot be converted from type 'int' to type 'varchar(30)', Error_code: 1677
2017-04-07T10:51:14.879633Z 5 [Warning] WSREP: RBR event 3 Write_rows apply warning: 3, 982675
2017-04-07T10:51:14.879730Z 5 [Warning] WSREP: Failed to apply app buffer: seqno: 982675, status: 1
at galera/src/trx_handle.cpp:apply():351
Retrying 4th time
2017-04-07T10:51:14.879911Z 5 [ERROR] Slave SQL: Column 1 of table 'sbtest1.sbtest1' cannot be converted from type 'int' to type 'varchar(30)', Error_code: 1677
2017-04-07T10:51:14.879924Z 5 [Warning] WSREP: RBR event 3 Write_rows apply warning: 3, 982675
2017-04-07T10:51:14.885255Z 5 [ERROR] WSREP: Failed to apply trx: source: 938415a6-1aab-11e7-ac29-0a69a4a1dafe version: 3 local: 0 state: APPLYING flags: 1 conn_id: 125559 trx_id: 2856843 seqnos (l: 392283, g: 9
82675, s: 982674, d: 982563, ts: 146831275805149)
2017-04-07T10:51:14.885271Z 5 [ERROR] WSREP: Failed to apply trx 982675 4 times
2017-04-07T10:51:14.885281Z 5 [ERROR] WSREP: Node consistency compromized, aborting…As can be seen, Galera complained about the fact that the column cannot be converted from INT to VARCHAR(30). It attempted to re-execute the writeset four times but it failed, unsurprisingly. As such, Galera determined that the node consistency is compromised and the node is kicked out of the cluster. Remaining content of the logs shows this process:
2017-04-07T10:51:14.885560Z 5 [Note] WSREP: Closing send monitor...
2017-04-07T10:51:14.885630Z 5 [Note] WSREP: Closed send monitor.
2017-04-07T10:51:14.885644Z 5 [Note] WSREP: gcomm: terminating thread
2017-04-07T10:51:14.885828Z 5 [Note] WSREP: gcomm: joining thread
2017-04-07T10:51:14.885842Z 5 [Note] WSREP: gcomm: closing backend
2017-04-07T10:51:14.896654Z 5 [Note] WSREP: view(view_id(NON_PRIM,6fcd492a,37) memb {
b13499a8,0
} joined {
} left {
} partitioned {
6fcd492a,0
938415a6,0
})
2017-04-07T10:51:14.896746Z 5 [Note] WSREP: view((empty))
2017-04-07T10:51:14.901477Z 5 [Note] WSREP: gcomm: closed
2017-04-07T10:51:14.901512Z 0 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2017-04-07T10:51:14.901531Z 0 [Note] WSREP: Flow-control interval: [16, 16]
2017-04-07T10:51:14.901541Z 0 [Note] WSREP: Received NON-PRIMARY.
2017-04-07T10:51:14.901550Z 0 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 982675)
2017-04-07T10:51:14.901563Z 0 [Note] WSREP: Received self-leave message.
2017-04-07T10:51:14.901573Z 0 [Note] WSREP: Flow-control interval: [0, 0]
2017-04-07T10:51:14.901581Z 0 [Note] WSREP: Received SELF-LEAVE. Closing connection.
2017-04-07T10:51:14.901589Z 0 [Note] WSREP: Shifting OPEN -> CLOSED (TO: 982675)
2017-04-07T10:51:14.901602Z 0 [Note] WSREP: RECV thread exiting 0: Success
2017-04-07T10:51:14.902701Z 5 [Note] WSREP: recv_thread() joined.
2017-04-07T10:51:14.902720Z 5 [Note] WSREP: Closing replication queue.
2017-04-07T10:51:14.902730Z 5 [Note] WSREP: Closing slave action queue.
2017-04-07T10:51:14.902742Z 5 [Note] WSREP: /usr/sbin/mysqld: Terminated.Of course, ClusterControl will attempt to recover such node – recovery involves running SST so incompatible schema changes will be removed, but we will be back at the square one – our schema change will be reversed.
As you can see, while running RSU is a very simple process, underneath it can be rather complex. It requires some tests and preparations to make sure that you won’t lose a node just because the schema change was not compatible.



